📊 Full opportunity report: Undervolting Your GPU for Local Inference: Lower Heat, Same Tokens/sec on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
Undervolting and power limiting GPUs during inference can significantly lower heat and noise without sacrificing much performance. Starting with power limits is the safest, easiest method, with undervolting offering further gains for advanced users.
Recent testing confirms that undervolting GPUs using power limiting during local AI inference significantly reduces heat output and noise with minimal impact on tokens per second, offering an accessible way to improve system efficiency.
Multiple developers and testing labs have demonstrated that lowering the power limit of high-performance GPUs, such as the NVIDIA RTX 4090 and RTX 5090, results in substantial reductions in temperature and fan noise, often with less than 10% performance loss during inference workloads. This is because most local large language model (LLM) inference tasks are memory-bandwidth-bound rather than compute-bound, meaning the GPU’s core clock speed is not the primary bottleneck. As a result, reducing power and voltage has little effect on tokens per second, which are the key performance metric for inference.
One verified approach involves adjusting the GPU’s power limit slider via tools like MSI Afterburner, which safely caps power consumption without risking damage or instability. Data shows that setting the power limit to around 50-55% yields optimal efficiency, dropping power use by up to 40-50% while maintaining over 90% of peak inference speed. For example, an RTX 4090 running at 70% power limit consumes 300W and operates at 98.6% of baseline speed, with a temperature reduction of about 5°C. Similar results have been observed with higher-tier cards like the RTX 5090.
This method is reversible and straightforward, making it suitable for most users. More advanced users may pursue undervolting by directly editing the GPU’s voltage-frequency curve for further optimization, but this requires testing for stability and is not recommended for beginners.
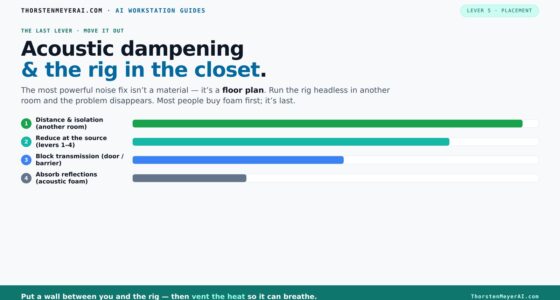
Undervolt for inference:
lower heat, same tokens/sec.
Local inference is memory-bound — the GPU core spends much of its time waiting on VRAM, not maxing out compute. So when you cap its power, heat falls fast while throughput barely moves. Drag the slider in Part 2 to see the trade for yourself.
(the real limit)
(often waiting)
you pay for in heat
| Power limit | Power draw | Temp | Speed kept | Efficiency |
|---|---|---|---|---|
| 100% (stock) | 390 W | 72°C | 100% | baseline |
| 80% | 330 W | 70°C | 98.6% | +17% |
| 70%recommended | 300 W | 67°C | 93.4% | +22% |
| 60% | 260 W | 62°C | 91.5% | +37% |
| 55%peak efficiency | 240 W | 60°C | 89.2% | +45% |
| 50% | 220 W | 58°C | 82.6% | +46% |
| 40% (too far) | 180 W | 52°C | 61.3% | falls off |
- One slider, 100% → 70%. The card reduces voltage and clocks on its own.
- Can’t damage anything — you’re restricting the card, not pushing it.
- No stability testing needed.
- Captures most of the available benefit.
- Edit the voltage-frequency curve — hold a clock at lower voltage.
- Target around 0.9–0.95V to start; better chips go lower.
- Keeps more performance for the same heat cut.
- Test under your real workload — a curve stable for 10 min can fail on hour 3.
MSI Afterburner (works on any brand). Headless Linux: nvidia-smi or LACT.sudo nvidia-smi -pl 300.Why Undervolting Matters for AI Inference Setups
This development is significant because it offers a practical way to improve the thermal and acoustic profile of AI workstations without sacrificing performance. Lower heat output reduces the need for aggressive cooling solutions, extends hardware lifespan, and decreases energy consumption. For users running inference workloads all day, these improvements translate into quieter, more efficient, and more sustainable systems, which is especially valuable in office or shared environments.
Given that most inference tasks are memory-bound, the ability to safely reduce power and voltage without impacting throughput means users can optimize their setups for long-term operation, lower operational costs, and reduced environmental impact. This approach also makes high-performance AI hardware more accessible to smaller labs and individual researchers who may be limited by cooling or noise constraints.
NVIDIA GPU undervolting software
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Background on GPU Power and Inference Performance
Modern high-end GPUs like NVIDIA’s RTX 4090 and RTX 5090 are factory-tuned with conservative voltage and clock settings to ensure stability across all units. These settings often result in excess heat and power consumption, especially during continuous inference workloads, which are memory-bound rather than compute-bound. Prior to this, most guides focused on gaming performance, where lowering core clocks can cause noticeable frame rate drops. However, inference workloads differ, as they rely more heavily on memory bandwidth than raw GPU compute power.
Recent research and practical testing have shown that reducing power limits can cut heat and noise substantially while maintaining near-maximal inference speed. This insight is rooted in understanding the bottleneck difference between gaming and AI inference, enabling more targeted and effective power management strategies.
"Most local inference workloads are memory-bandwidth-bound, so lowering core voltage and clock speeds doesn't impact tokens per second significantly."
— Thorsten Meyer, AI hardware tuning expert
GPU power limit adjustment tool
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Remaining Questions on Long-Term Stability and Compatibility
While short-term tests show promising results, it remains unclear how sustained undervolting and power limiting affect hardware longevity over months or years. Additionally, compatibility with different GPU models and future driver updates may influence the effectiveness and safety of these methods. More comprehensive long-term studies are needed to confirm durability and stability under continuous inference workloads.
MSI Afterburner for GPU tuning
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps for Users and Developers
Users are encouraged to start with simple power limiting adjustments using tools like MSI Afterburner to evaluate heat and noise improvements. Further research will likely explore automated undervolting profiles and more sophisticated tuning methods. Hardware manufacturers and driver developers may also optimize firmware to better support inference-specific power management, potentially making these adjustments more accessible and reliable in future updates.
GPU temperature monitoring hardware
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Can undervolting damage my GPU?
No, undervolting and power limiting are reversible and do not physically damage the GPU. They simply restrict power and voltage within safe, manufacturer-defined limits.
Will I notice a performance drop during inference?
Most users will see minimal to no noticeable performance loss—typically less than 10%—because inference workloads are memory-bound, not compute-bound.
How do I start undervolting or power limiting my GPU?
Begin with tools like MSI Afterburner to adjust the power limit slider safely. For undervolting, more advanced editing of the voltage-frequency curve is possible but requires stability testing and experience.
Does this approach work with all GPUs?
While most modern NVIDIA GPUs benefit from power limiting during inference, results may vary based on model, firmware, and workload specifics. Always test carefully.
Is this recommended for gaming or only inference?
This technique is primarily beneficial for inference workloads; gaming performance can be more sensitive to core clock reductions, so caution is advised when applying to gaming setups.
Source: ThorstenMeyerAI.com